Since the mid 90s, clusters are a popular hardware platform to compute-intensive applications, but the power
consumption of these machines has already reached an unacceptable amount. In 2007 it was already estimated that
the ICT Industry is already responsible for 2% of the global CO2 emission.
The High-Performance community is aware of this conflict. As a complement to the list of the 500 fastest machines, the
Green500
compares supercomputers by their performance-per-watt since November 2007.
CHERUB - an energy saving daemon for HPC- and SLB-clusters
Compute clusters are often managed by a so-called Resource Management System (RMS) which has load information
about the whole system. CHERUB is a centralized daemon which is installed on top of an arbitrary RMS and uses its
load information to switch on/off nodes according to the current load situation and load forecasting to save
energy in this way. Due to its modular design and its well defined API it can operate with different Resource
Management Systems. At the Moment there are modules available for the Portable Batch System (PBS), the Load
Sharing Facility (LSF) and the IBM Load Leveler (LL) in the High Performance Compute (HPC) field and for the
Linux Virtual Server (LVS) in the Server Load Balancing (SLB) field.
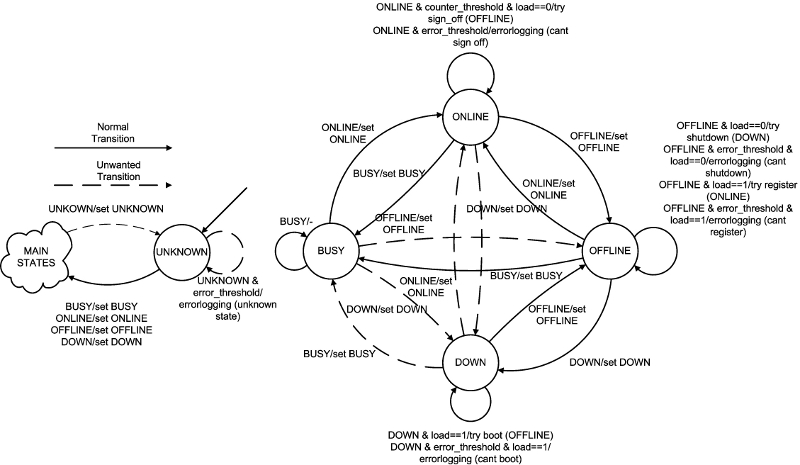
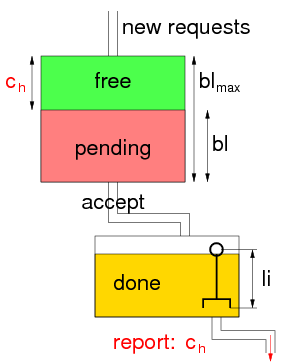
CHERUB uses 5 internal states to manage the nodes of a cluster. The relation between these states can be seen in Fig.1 below.
Image
Fig.1: Different Cherub States
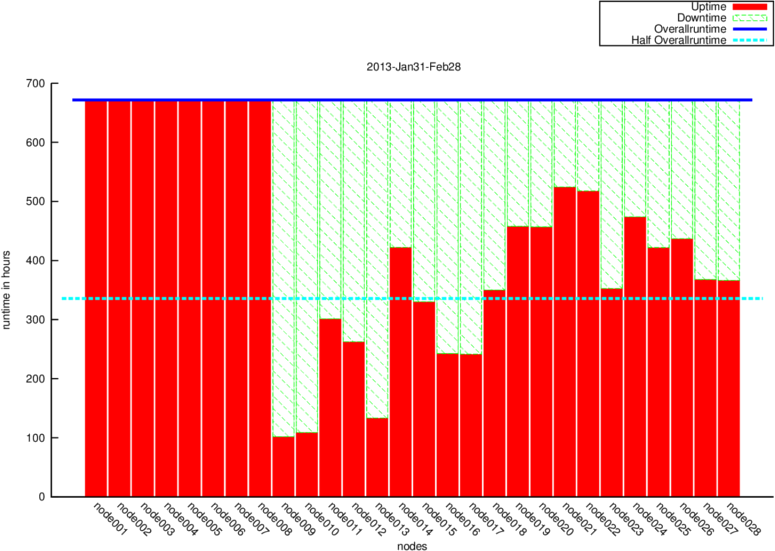
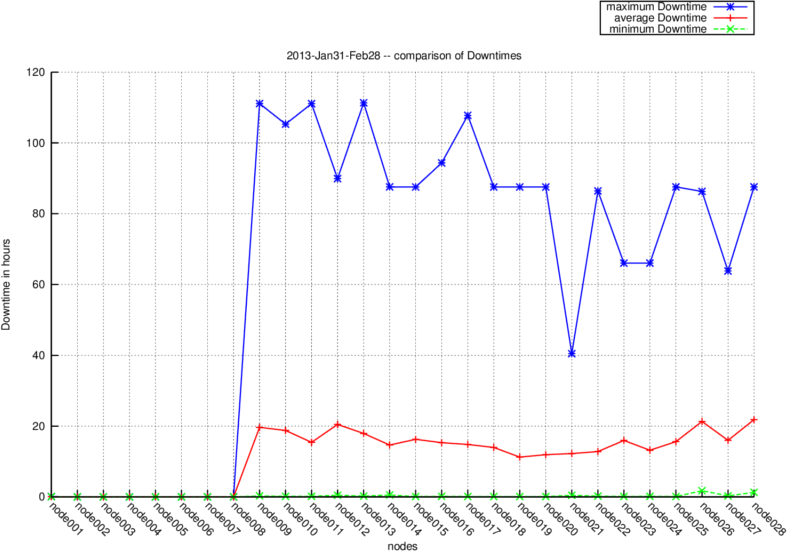
Our experimental results shown in Fig. 2 and 3 prove that Cherubs energy management works fine, i.e. it will save energy if
possible (Fig. 2) and avoids state-flipping (Fig. 3). Within the experiment node001-node008 where configured to be powered on
all the time. While the cluster was doing normal business CHERUB was able to save around 48% of energy (not considering the
always on nodes).
Image
Fig.2: Energy Saved with CHERUBFig.3: Downtime of nodes when managed with CHERUB
At the moment, Cherub is used on the cluster of the Institute of Computer Science at the University of Potsdam (cluster managed
by the Portable Batch System (PBS)) and the German Research Centre for Geosciences at Potsdam (cluster managed by the Load
Sharing Facility (LSF)).
Current development efforts are focused on optimizing the Linux Virtual Server module for Server Load Balancing scenarios by
using load forecasting and backup features.
The current version (1.3.11) of Cherub can be found
here.
If you have any questions regarding CHERUB feel free to contact the developer at simon.kiertscher(at)cs.uni-potsdam.de.
Publications - HPC
Power Consumption Aware Cluster Resource Management
Simon Kiertscher, Jörg Zinke and Bettina Schnor
Bookchapter in Energy-Aware Systems and Networking for Sustainable Initiatives, ISBN-13: 9781466618428
IGI-Global, December 2012
CHERUB: power consumption aware cluster resource management
Simon Kiertscher, Jörg Zinke and Bettina Schnor
Journal of Cluster Computing, ISSN: 1386-7857
Springer Netherlands, September 2011
Cherub: Power Consumption Aware Cluster Resource Management
Simon Kiertscher, Jörg Zinke, Stefan Gasterstädt and Bettina Schnor
IEEE/ACM International Conference on Green Computing and Communications
Hangzhou, China, December 2010
Publications - SLB
Scalability Evaluation of an Energy-Aware Resource Management System for Clusters of Web Servers
Simon Kiertscher and Bettina Schnor
International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS)
Chicago, USA, July 2015
Energy Aware Resource Management for Clusters of Web Servers
Simon Kiertscher and Bettina Schnor
IEEE International Conference on Green Computing and Communications, page 148-156
Beijing, China, August 2013
Intel SCC
The group is member of the Intel
Many-Core Research Architecture Community (MARC) and has physical access to a loaned Intel 48-core
Single-Chip Cloud Computer (SCC). The SCC is an experimental processor with 48-cores, developed by Intel
Labs as a platform for many-core software research. The SCC has special hardware support for message
passing and energy management.
The group is working on "Parallel Programming Patterns suited for SCC". We want to identify
parallelization patterns and/or communication patterns which are best suited for the SCC and
result in scaling applications. In cooperation with the
Potsdam Institute of climate impact (Group of Prof. Rahmsdorf) we investigate the scaling of Aeolus on the SCC.
Intel has delivered an implementation of the Message Passing Interface Standard (MPI) called RCKMPI.
We have developed an optimization of RCKMPI that improves the communication bandwidth by evaluating
the application's communication graph and making optimal use of SCCs Message Passing Buffers. Further,
the memory subsystem allows versatile configurations and enables the usage globally shared memory.
We investigate an efficient usage of the memory configuration for parallel applications.
Publications
Synchronization of One-Sided MPI Communication on a Non-Cache Coherent Many-Core System
Steffen Christgau and Bettina Schnor
12th Workshop on Parallel Systems and Algorithms (PASA)
Nürnberg, Germany, April 2016
Software-managed Cache Coherence for fast One-Sided Communication
Steffen Christgau and Bettina Schnor
7th International Workshop on Programming Models and Applications for Multicores and Manycores
Barcelona, Spain, March 2016
One-Sided Communication in RCKMPI on the SCC
Steffen Christgau and Bettina Schnor
6th Many-core Applications Research Community Symposium
ONERA Toulouse, France, July 2012
Awareness of MPI Virtual Process Topologies on the Single-Chip Cloud Computer
Steffen Christgau and Bettina Schnor
17th International Workshop on High-Level Parallel Programming Models and Supportive Environments (HIPS) at IPDPS 2012
Shanghai China, May 2012
The Benefit of Topology-Awareness of MPI Applications on the SCC
Steffen Christgau, Bettina Schnor and Simon Kiertscher
3rd Many-core Applications Research Community Symposium
Ettlingen, Germany, July 2011
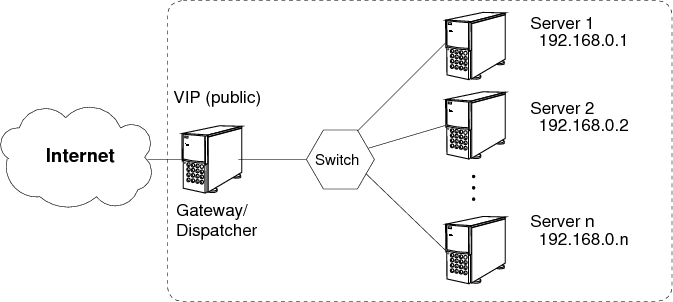
salbnet: Self-Adapting Load Balancing Network
Server Load Balancing (SLB) is an efficient way to provide scalable and fault tolerant services.
The traffic of a site is distributed among a number of servers connected via network.
Image
Fig.1: Server Load Balancing Scenario
Usually, the Load Balancer distributes the load to the back-end servers in a round-robin fashion or
according to current server load based on external load parameters. The use of server weights is very
popular to improve the load balancing in case of heterogeneous server machines. Correctly determined
weights are crucial to the quality of the distribution. While the determination of weights can be done
in small and static environments, it can hardly be done in dynamic or heterogeneous environments.
Image
Fig.2: Server Load Balancing Scheme
Often, the load balancing environment is very heterogeneous, since new machines are added at the time
the number of servers becomes insufficient. Current approaches use server weights to distinguish the
fast from the slow machines. The problem with static weights is that they strongly depend on the
application, the kind of requests, the back-end network interconnect, and the server's capabilities.
Non-exact weights significantly reduce the quality of the distribution, resulting in increased answer
time, more dropped requests, and unbalanced usage of servers.
More sophisticated approaches choose the server on the basis of measured load indicators, but to the
price of less scalable algorithms with a complexity of O(n).
We propose a credit-based load balancing scheme that is self-adapting and is basing on an O(1) algorithm,
that is able to self-adapt to heterogeneous servers and heterogeneous workloads without the need to
specify server weights.
Server Load Balancing for InfiniBand Networks
InfiniBand is an evolving high speed interconnect technology to build high performance computing clusters.
Network interfaces (called host channel adapters) provide transport layer services over connections and
datagrams in reliable or unreliable manner. Additionally, InfiniBand supports remote direct memory access
(RDMA) primitives that allow for one-sided communication.
For InfiniBand-Cluster, salbnet uses the RDMA-feature to update credits to the dispatcher.
Publications
Self-Adapting Load Balancing for DNS
Jörg Jung, Simon Kiertscher, Sebastian Menski and Bettina Schnor
Journal of Networks
April 2015 Extended journal version of SPECTS 2014
Self-Adapting Load Balancing for DNS
Jörg Jung, Sebastian Menski, Bettina Schnor and Simon Kiertscher
International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS)
Monterey, USA, July 2014 Best Paper
salbnet: A Self-Adapting Load Balancing Network
Jörg Jung, Bettina Schnor and Sebastian Menski
In Proceedings of the 12th Conference on Parallel and Distributed Computing and Networks (PDCN)
Innsbruck, Austria, February 2014
The Impact of Weights on the Performance of Server Load Balancing Systems
Jörg Zinke and Bettina Schnor
International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS)
Toronto, Canada, July 2013
System call tracing overhead
Jörg Zinke, Bettina Schnor and Simon Kiertscher
UpTimes 2/2009 - In Proceedings of the international Linux System Technology Conference and OpenSolaris Developer Conference, ISBN: 3865413587, ISBN-13: 9783865413581
Dresden, Germany, October 2009
Self-Adapting Credit Based Server Load Balancing
Lars Schneidenbach, Bettina Schnor, Jörg Zinke and Janette Lehmann
In Proceedings of the 26th Conference on Parallel and Distributed Computing and Networks (PDCN)
Innsbruck, Austria, February 2008
Self-Adapting Server Load Balancing in InfiniBand Networks
Lars Schneidenbach and Bettina Schnor
Technical Report, Universität Potsdam, ISSN: 0946-7580, TR-2007-2
Potsdam, Germany, 2007
SLIBNet: Server Load Balancing for InfiniBand Networks
Sven Friedrich, Lars Schneidenbach and Bettina Schnor
Technical Report, Universität Potsdam, ISSN: 0946-7580, TR-2005-12
Potsdam, Germany, 2005
servload: Service Benchmarking
servload is a lightweight (∼ 2000 SLOC ANSI C) high performance service benchmark which supports the
protocols HTTP and DNS. servload uses requests and responses to determine performance metrics.
Furthermore servload loads (and may modify) a given log file and issues (replay) the resulting requests.
The current version of servload can be found here.
See INSTALL file for further hints on installation from source and manual page for usage details.
Publications
servload: Generating Representative Workloads for Web Server Benchmarking
Jörg Zinke, Jan Habenschuß and Bettina Schnor
International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECT)
Genoa, Italy, July 2012
OpenBSD PF Development
The OpenBSD Packet Filter (PF) can also be used as load balancer. We integrated Weighted Round Robin
and the Least States algorithms for PF. It is part of the OpenBSD implementation since release 5.0.
Further information can be found in Fabian Hahns diploma thesis (in German).
VoIP Security Architecture
Voice over IP (VoIP) - telecommunication over the internet - has grown up very fast in the short past.
The main reason for this development is that the costs for broadband connections decrease and often
VoIP accounts are given for free.
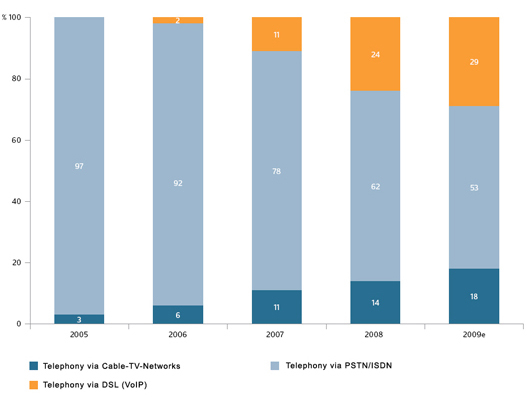
The diagram in Fig. 1 shows the increasing number of VoIP connections in comparison to the decreasing
number of PSTN (Public Switched Telephone Network) connections.
Image
Fig.1: Development in telephony communication
Goals and Challenges
VoIP service quality equal to landline PSTN/ISDN
consumer protection via:
detection and prevention of SPAM over Internet Telephony (SPIT)
mutual end-to-end authentication
detection and enforcement of media connectivity
development of prototypes within existing software solutions:
Kamailio SIP Server (used by 1&1, sipgate and freenet)
PJSIP SIP Stack (used by apps for iphone, itouch and android phones)
Research Environment
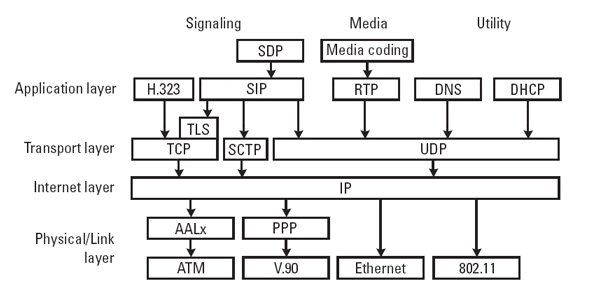
The establishment of a VoIP communication consists of signalling and media streaming. The development
of our secure VoIP Architecture is mainly based on a SIP (Session Initiation Protocol) environment.
In this context SIP is used for signalling. The media data are transmitted via RTP (Real-Time Transport Protocol).
Image
Fig.2: Internet Multimedia Protocal Stack
Figure based on: Alan B. Johnston. SIP - Understanding the Session Initiation Protocol,
2. Edition. In Artech House telecommunications library, Artech House, 2004 Compare chapter 1.4, figure 1.1
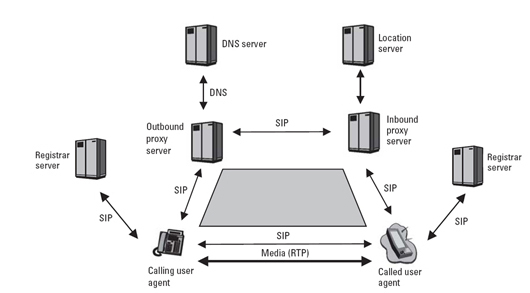
Image
Fig.3: SIP Infrastructure
Figure based on: Alan B. Johnston. SIP - Understanding the Session Initiation Protocol, 2. Edition.
In Artech House telecommunications library, Artech House, 2004 Compare chapter 3.5, figure 3.2 and figure 3.3
Detection and Prevention of SPAM over Internet Telephony (SPIT)
Decreasing prices for VoIP communication in combination with a fast growing community will result in the same
affliction as e.g. e-mail has been: the more potentially reachable people make it more worth to send them SPAM
messages (e.g. unsolicited advertising). In addition VoIP will replace the classical telephony infrastructures
in ever-growing numbers. In the course of this infrastructure change SPAM over Internet Telephony (SPIT) will
be massively spread.
The fact that already the request for a call, which is usually indicated by the ringing of the phone, might
already be a disturbance or annoyance of the called party is a serious problem. Therefore classical preventive
and defensive measures are not effective anymore. Thus it is necessary to research appropriate counter measures.
For e-mail communication, SPAM prevention has been covered much too late. This mistake should not be repeated
with VoIP. Even before SPIT intensifies there must be capable solutions that can defend spit effectively.
Thus a first work analyzed PSTN, ISDN, e-mail and VoIP protocols as well as SPAM and SPAM prevention mechanisms
to find out how SPIT can appear and how to prevent it. Various (known and new) solutions to prevent SPAM were
examined and analyzed for their qualification to prevent SPIT. Finally two SIP extensions are proposed. They
enable SIP applications a) to request the provider's appraisement for spit calls and b) to request some compensation fee.
A second work designed classification criteria for unsolicited calls and introduces a system that based on these
criteria estimates the probability of SPIT. This rating is used as a reference point for the caller to decide
whether he accepts the call or not.
Finally a third work based on the previous works (and other related work), deals with a complete concept for the
detection and avoidance of unsolicited calls. Thereby the majority of the preventive measures are used on the
side of the provider. Several different filter measures and a rating system are described in detail. For that
purpose the Session Initiation Protocol (SIP) is examined, which has prevailed for communication in VoIP
infrastructues While the filter measures are based on concepts from the world of emails, the rating system is an
approach which evaluates the behaviour of the caller in the past. The valuation criteria are structured modular
due to their diversity and based on conclusions from the analysis of real telephone services. The results of the
individual evaluations by the modules are summarized in an indicator for the SPIT probability. This value is then
transmitted to the called user with the call request. The callee decides on the consequence from the determined
SPIT probability. The concepts presented in this work are realized by implementing an extension for the Kamailio
SIP server. The Kamailio SIP server is used productively by well-known Internet service providers and has become
a kind of standard in this area.
Mutual End-to-End Authentication
The authentication of communication partners is a basic requirement to establish trust relationsships in Internet
services. For example, it is necessary for correct payment and forensics. Within a VoIP infrastructure the
authenticity of the involved endpoints affects different aspects of information security . Furthermore, authenticity
is necessary for detecting and avoiding SPAM over Internet Telephony (SPIT). Only if the identity of a caller can
be verified reliably, a spitter can be exposed and appropriate countermeasures can be taken.
In this work different approaches for authentication within a VoIP infrastructure are analyzed and developed.
This work is mainly based on the Session Initiation Protocol (SIP). The discussed concepts are compared on the
basis of various criteria. As the result of that analysis an authentication mechanism was developed which supports
both: end-to-end mutual authentication between caller and callee, and between SIP client and SIP provider.
For that purpose, we use a decentralized approach based on PGP (Pretty Good Privacy).
Our concept is realized in a prototype implementation by using an existing SIP software. As the underlying proxy
implementation the Kamailio (Open SER) Open Source SIP Server is used. The user agent is based on the PJSIP -
Open Source SIP Stack.
Detection and Enforcement of Media Connectivity
When using the Session Initiation Protocol (SIP) for Internet telephony (VoIP), media streams between the endpoints
may be blocked even if a session can be successfully established. Because SIP does not check for media connectivity,
a provider routing the call does not know the connectivity status, but this would be useful for payment and Spam over
Internet Telephony (SPIT) prevention. Existing mechanisms like Interactive Connectivity Establishment (ICE) are not
sufficient to allow a SIP proxy to reliably determine the connectivity status. A SIP extension is developed that
achieves this by multiplexing all media streams over a single connection between the endpoints using the
connection-oriented transport protocol SCTP, and by delaying session establishment until the connection is established.
Measurements show that the Linux Kernel SCTP implementation exhibits adequate performance for transporting real-time
media compared to UDP. Connectivity enforcement is used to prevent endpoints from forging the connectivity status.
A mechanism is devised as part of the SIP extension to allow the proxy to enforce the desired user agent behavior using
existing SIP features; a prototype of the mechanism has been implemented using the Kamailio SIP Proxy.
Publications
SIP Providers' Awareness of Media Connectivity
Stefan Gasterstädt, Markus Gusowski and Bettina Schnor
Tenth International Conference on Networks (ICN)
St. Maarten, The Netherlands Antilles, 2011
Architecture for the Privacy-Aware Sharing of Electronic Patient Data
Motivation
Sharing private electronic data between different actors is becoming the norm in a large number of real world use-cases.
However, there exist several areas of life, where private data is considered sensitive and additional data protection
should be provided through privacy-aware data exchange mechanisms. One application domain where this is true is the
protection of private medical data.
Electronic Personal Health Records offer many potential benefits for the patient. Patients can maintain a store of
relevant data concerning their medical history, medication and treatments. Sharing this information with practitioners
and medical consultants could facilitate better and faster treatment and may make life easier for the patient or a
caring custodian.
The potential benefit of Personal Health Record is offset by legitimate privacy concerns against the indiscriminate
sharing and use of private health data. An ideal sharing system would allow the patient to express fine-grained access
policies - according to his or her perceived privacy need. The shared data should stay under the control of the patient,
so that non-conforming further use of the data becomes impossible. A reference monitor implementation would automatically
enforce the data-use policy of the patient.
The gathering, usage and distribution of private medical data is permitted only with the explicit consent of the patient.
In many cases the patient waives this rights by signing broad data sharing agreements with health care providers and
practitioners.
It is our aim to enable the patient to retain control over this data sharing process. The patient should be able to
express, modify and revoke explicit access rights that will be enforced by a privacy-enabled Personal Health Record
system. The patient decides what data items should be shared with data users and would be able to restrict access
rights accordingly.
The management of the generated data-access policies is another important aspect. Current health record systems
(such as Google-Health) use a central server architecture, where data and corresponding policies are stored. Maintaining
a strong binding between data and access policy becomes difficult in this model.
Image
Fig.1: Privacy Motivation
Research Area
Based on the use-case of a mobile, electronic Personal Health Record we developed a distributed access control system
that allows the specification of usage policies by the data owner.
Usage control is enforced through a prototypical reference monitor that facilitates client-side access and usage
control. Patient data can be distributed throughout our systems and each data access location is able to derive
valid access control decisions without the need to access a central policy-server.
The expression of meaningful privacy policies is a non-trivial problem, especially if we expect ordinary users
to maintain a privacy policy close to their natural intuition. We therefore research mechanisms for the safe
expression of policies with different hierarchical scope.
The automatic enforcement of privacy policies by the application framework is another important research topic.
We analysed different access control and security models before we developed a suitable architecture that enforces
data usage-restrictions derived from the privacy policy.
Image
Fig.2: Privacy Research
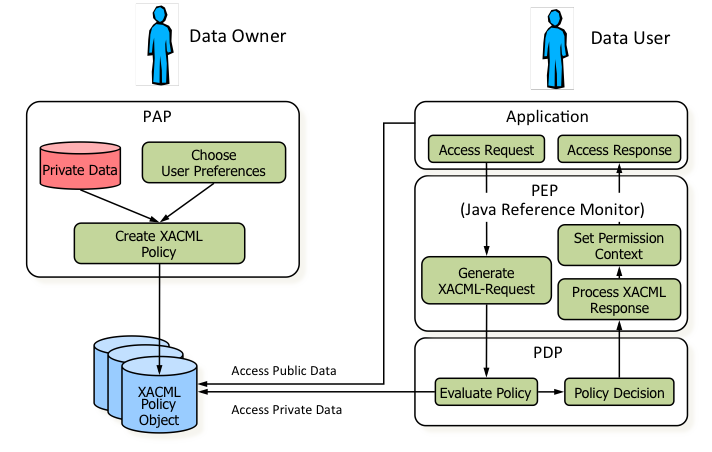
Architecture
A distributed reference monitor is a practical method for the enforcement of data-owner controlled access-rights
for distributed data in open communication systems. Our system specifies access policies, based on the XACML policy
description language, which are evaluated to an access-decision by the reference monitor.
Patient-data and corresponding access rights will be combined into a single XML-object. The data-owner created access
rights are stored as an XACML-policy, that directly references the XML-encoded patient data in the same container.
This policy stays attached when the data object itself is copied or distributed to the data user. Privacy rules can be
consulted whenever local access-decisions have to be made by the reference monitor.
This architecture allows us to bind the actions of the data user to the privacy rules of the data owner. We can specify
specific views on the Health Record data and effectively restrict privacy threatening data usage (such as further
distribution, storage and modification). Our scheme enables the data owner to formulate clear and explicit privacy
policies that are inline with his or her personal demands and reliably enforce these polices.
Image
Fig.3: Privacy Architecture
Implementation
The client-side reference monitor uses a modified Java Security Manager for the enforcement of usage restrictions.
XACML-privacy policies will be translated into corresponding Java Permissions that are compatible with the existing
Java Security Architecture. The client-side application of the data-user is started under the control of the Java
Security Manager, which takes care that only authorized actions are performed by the application. The XML data-object
can only be accessed via the reference monitor and will be protected by XML-Encryption.
Publications
Privacy Enforcement with Data Owner-defined Policies
Thomas Scheffler [PhD Thesis]
NEON: One Sided Communication in Parallel Applications
In current research, one sided communication of the MPI2 standard is pushed as a promising technique.
But measurements of applications and MPI2 primitives show a different picture. We analyzed design issues
of MPI2 one sided communication and its implementations with focus on asynchronous communication for
parallel applications in Gigabit Ethernet cluster environments. Further, one sided communication is
compared to two sided communication. Our investigations show that the key problem to performance is not
only the implementation of MPI2 one sided communication - it is the design.
MPI2 implementations of one sided communication prove themselves to be inefficient on Ethernet based
clusters. The main issue is the violation of the pipeline model by deferring data transfers. But this
deferral is the consequence of the MPI2 standard that requires additional synchronization otherwise.
This means that the specified MPI2-OSC API is not efficiently implementable for Ethernet clusters and
is therefore not portable without performance loss.
Currently, we work on NEON (NEw ONe sided communication interface), a communication system and API that
supports one sided communication to prove the impact of the above mentioned design issues.
Measurement Tool
The current version of eins, a tool for measuring network-bandwidths and -latencies, can be found
here.
Publications
The Benefits of One-Sided Communication Interfaces for Cluster Computing
Lars Schneidenbach [PhD Thesis]
Design Issues in the Implementation of MPI2 One Sided Communication in Ethernet based Networks
Lars Schneidenbach and Bettina Schnor
In Proceedings of the 25th Conference on Parallel and Distributed Computing and Networks (PDCN)
Innsbruck, Austria, February 2007
Cluster Computing Exploiting Gigabit Ethernet
Since communication is one of the crucial points in parallel computation, fast networks and fast communication
protocols are one of the key issues in cluster computing. At the University of Potsdam, Gigabit Ethernet is
investigated as a System Area Network (SAN). Typically, Gigabit Ethernet is used as a backbone technology
connecting different LANs. It is based on the well-experienced Ethernet technology, offering an impressive
bandwidth of 1 GBit/s under moderate costs. Its latest "child" is even capable of
10 GBit/s.
Leightweight Messaging Systems
Standard TCP/IP protocols over Fast/Gigabit Ethernet incur a high overhead, resulting in high communication
latency and poor bandwidth utilisation.
Instead, Lightweight Protocols are investigated for cluster communication:
Minimizing message processing overhead
Based on the concept of Active Messages computation and communication are processed asynchronously
In cooperation with the University of Genoa the lightweight protocol Gamma
(
GAMMA: The Genoa Active Message MAchine) is ported to the Netgear 621 card. First measurements show an asymptotic bandwidth
of 115 Mbyte/s on the Uranus cluster.
Fast Socket Communication over Gigabit Ethernet
Thanks to leightweight protocols like GAMMA, we can achieve brilliant latency and bandwidth values on top of
Gigabit Ethernet. While GAMMA supports the important class of MPI based parallel applications via the MPI/GAMMA
interface, the support of socket based cluster applications is still missing. Examples for this class of
applications are for example webservers, distributed file systems and distributed redundant storage.
Current research is done to investigate how the Socket Interface ban be implemented on top of GAMMA.
Publications
Architecture and Implementation of a Socket Interface on top of GAMMA
Stefan Petri, Lars Schneidenbach and Bettina Schnor
In Proceedings of the 28th Annual IEEE Conference on Local Computer Network
Bonn, Germany, October 2003
Exploiting Gigabit Ethernet Capacity for Cluster Applications
G. Ciaccio, Marco Ehlert and Bettina Schnor
In Proceedings of the 27th Annual IEEE Conference on Local Computer Network
Florida, USA, November 2002
: A Reliable Grid Service Infrastructure
The Grid is dynamic by nature, with nodes shutting down respectively coming up again. The same holds for
connections. For long running compute-intensive applications fault-tolerance is a major concern. A benefit of
the Grid is that in case of a failure an application may be migrated and restarted on another site from a
checkpoint file. But a migration framework cannot support fault-tolerant applications, if it is not
fault-tolerant itself.
The Migol project is aimed to investigate the design and implementation of an fault-tolerant infrastructure,
i.e. without any single point of failure, conforming to the
Open Grid Service Architecture (OGSA) for supporting the migration of parallel MPI
applications. OGSA builds upon open Web service technologies to uniformly expose Grid resources as Grid services.
The Open Grid Services Infrastructure (OGSI) Open Grid Services Infrastructure (OGSI) is the
technical specification of extensions to the Web services technology fulfilling the requirements described by
OGSA. An implementation of the OGSI is provided by the Globus Toolkit 3 and 4 (GT3 resp. GT4).
Migol is a framework consisting of a set of Grid services and libraries that provides fault-tolerant services
to Grid applications. Migol services are currently built on top of GT3.
The key issues of Migol are:
Efficient replication strategies for data consistency in the Grid
Security: fault-tolerant credential repository
Efficient mapping heuristics for the allocation of resources in the Grid
Migol services can be accessed through the Migol portlet, a
portal application for the Gridsphere portal server.
Image
Fig.1: Migol Portlet
Publications
A Dependable Middleware for Enhancing the Fault Tolerance of Distributed Computations in Grid Environments
André Luckow [PhD Thesis]
Migol: A Fault-Tolerant Service Framework for MPI Applications in the Grid
André Luckow and Bettina Schnor
In Proceedings of Euro PVM/MPI and Lecture Notes in Computer Science
Capri, Italy, September 2005
Dynamic Load Balancing For Grid Applications
A grid application is a parallel application running on several parallel computers at different
geographically distributed sites. In cooperation with the Max-Planck-Institut for Gravitational
Physics dynamic load balancing and migration for grid applications are investigated.
In order to make better and more flexible use of computational resources, parallel codes can be
run in grid environments using distributed
MPI implementations.
However, performing such runs can be very cumbersome and demanding and mostly leads to a very poor
performance. This thesis tries to develop techniques to improve this situation.
A first successful demonstration of the application of those techniques in a large scaled high
performance run was done in april last year. The results of this demonstration run supported the
funding of the
Tera Grid.
They also led to further development of effective techniques for distributed computing, for which
the Gordon Bell Prize was awarded. The implementation of the new algorithms was done within
Cactus code using
the Globus metacomputing
toolkit.
Distributed Computations in a Dynamic, Heterogeneous Grid Environment
Thomas Dramlitsch [PhD Thesis]
Grid Migration: Nomadic Migration and Application Spawning
Nomadic Migration
Many large scale simulation in the field of hydrodynamics or meteorological modeling have compute time
requirements, which go way beyond the queue time limits of the compute hosts. The runtime may not even
be predictable at the start of the simulation.
This limitation requires the researcher to start the tedious process of securing the simulation's checkpoint
files and archiving them if necessary. If the simulation is continued on another host, checkpoint files need
to be transferred and the simulation is resubmitted to the queuing system.
At all steps, the user's manual interaction makes the process prone to failure:
Checkpoint files can be erased by disk quota time outs, the manual transfer of data takes long and resource
requirements have to be correctly analyzed. Last but not least, the researcher is required to remember usernames
and passwords as well as the interfaces to a wide range of different machines, architectures, queuing systems and
shell programs.
The process of resubmitting to an arbitrary host, which fulfills minimum resource requirements, is a prime candidate
for automation.
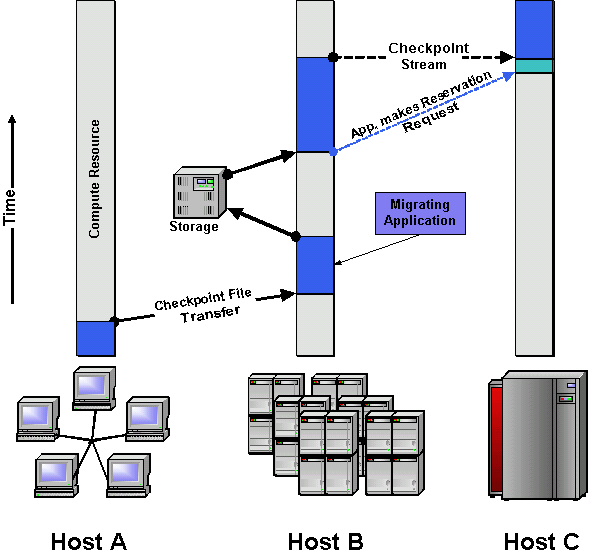
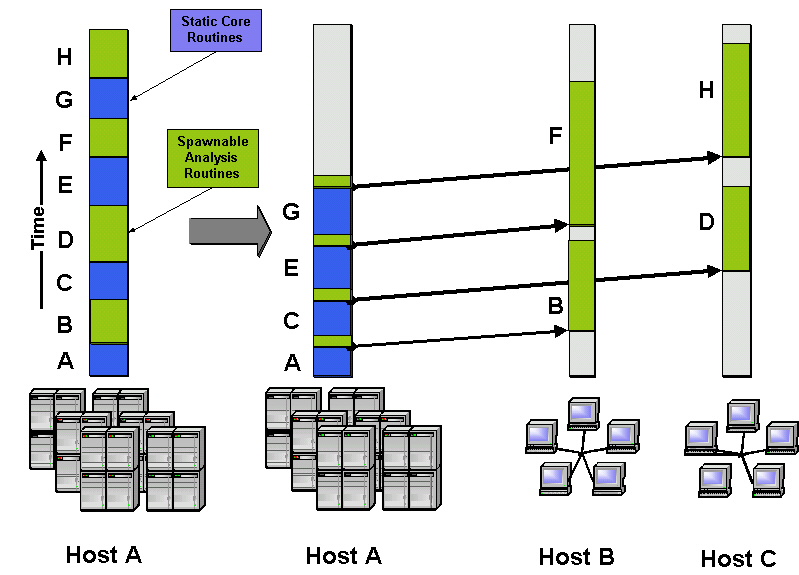
Such a process is illustrated in the Fig. below, which shows the time line of a migrating application (shaded area)
on three different hosts A, B and C. This host may have diverse types, here we sketched a cluster of workstations,
a cluster and a traditional supercomputer.
The simulation is started on host A and the migration server (not shown) receives information on the application's
resource consumption and location of the application. The migration server will monitor the availability of new machines,
which will meet the application's requirements and boost its performance.
As "better" resources become available, the simulation is informed and checkpoints. The checkpoint files are transferred
to host B, where the simulation is restarted. As the application runs out of compute time on B the checkpoint data is
archived in a storage facility and the simulation is resubmitted to the queue on the same machine.
Some advanced applications are able to receive the checkpoint as a socket stream instead of reading from file. In
combination with advanced reservation scheduling, this transfer mode allows for fast checkpoint transfer, shown in the
migration to machine C: The application on B is aware of the expiration of its queue time limit and requests a slot on
machine C, which overlaps with the compute slot on B. By the time the application is about to finish on B, the migration
server starts an uninitialized simulation on C, which receives the simulation state through the streamed checkpoint and
continues the calculation.
In any case, the server must determine the possible file transfer methods for each of the source and target machine, since
it will stage the executable and possibly a checkpoint to the new host. The migration server is also responsible for
submitting the new job to the queuing system. Previously written output must be transferred from the old host to a user
given destination.
Image
Fig.1: Intro Migration
In a nomadic migration scenario, the application profiles its performance and provides data such as disc usage or maximum
memory consumption. Since the application is moderately aware by which time the queue time is about to expire, it will engage
in a checkpointing procedure and inform a migration server about the upcoming migration.
The migration server receives information on the checkpoint files, executable and resource requirement.
It will look up an appropriate resource, stage checkpoint and executable to the new host and submit a new job. The
appropriate communication and queue system language is automatically chosen and previously written output data is transferred
to a user given destination.
Application Spawning
By taking advantage of parallelism in the application workflow, the application is split up in a set of sub-applications.
each sub-application is executed on a resource, which is best qualified for that type of task. At runtime, the spawning
application determines, which sub-tasks in its workflow do not feed back into the main simulation flow and can therefore be
spawned.
The simulation writes a reduced checkpoint, which only contains those data structures, which are necessary to complete the
spawned tasks. For this reason, spawned sub-jobs can be executed with reduced memory requirements. The checkpoint files and
information on the executables are used to restart the subjob on another resource. The new resource can be chosen to best
match the characteristics of the spawned subjobs, e.g. in terms processing architecture + power, disk capacity, etc.
Image
Fig.2: Intro Span
Publications
Nomadic Migration - A Service Environment for Autonomic Computing on the Grid
Gerd Lanfermann [PhD Thesis]
Grid Tools
Various Grid tools have been developed or adapted at the University Potsdam to ease deployment of Grid applications:
Gridmake:
In the Grid a great heterogenous variety of resources are involved. Even a 100 per cent portable source code must
be compiled again to create binaries for a certain platform. Gridmake can automatically distribute and compile
source code.
Ganglia:
In the Grid the characterization and monitoring of resources, services, and computations is very challenging
due to the considerable diversity, large numbers, dynamic behavior, and geographical distribution of the entities.
Hence, information services are a vital part of any Grid software infrastructure. At the University of Potsdam we
deployed Ganglia to monitor our cluster and Grid infrastructure.
Publications
Cluster- und Grid-Monitoring am Informatik Uni-Postdam Grid
Michael Andraschek, Stephan Gensch und Matthias Schulz, Semesterarbeit
Grid Initiatives
In the scope of Grid Computing the University Potsdam, Department for Operation and Distributed Systems participates
in a number of projects. The University Potsdam is actively involved in the following Grid Computing projects
and initiatives:
The group is a member of the DEDIS graduate school. DEDIS stand for "Dependable Embedded and Distributed Hardware/Software
Systems". DEDIS is a common initiative of the BTU Cottbus und University Potsdam.
Summary of DEDIS Concept
Embedded and distributed computer-based electronic sub-systems are the core of larger systems in transportation, manufacturing,
communication and even in appliances. The quality and dependability of the overall system is mainly based on the properties
of the "embedded" sub-systems, which are themselves a complex composite of electronic hardware, software and interconnects
(wire-based and wireless). The art of designing such embedded sub-systems for a high degree of dependability at reasonable
cost is partly understood at best and has not yet become a real focus in advanced and post-doctoral education at-large. A
comprehensive design technology requires interdisciplinary efforts ranging from materials and basic devices to software
technology. The proposed graduate school has the objective and the mission to promote interdisciplinary research in critical
topics by jointly defined doctoral projects, to link researchers in adjacent fields for a better overall comprehension and to
establish an innovative international PhD program of studies.
Work at University Potsdam
Centralized architectures are more easy to implement, but suffer from a single point of failure. Therefore, in mobile ad-hoc
networks (MANETs) no centralized infrastructure is utilized for package-routing. The connection inbetween the nodes is
established via wireless channels, which utilize common wireless standards like IEEE 802.11 or IEEE 802.15. Currently, MANET
protocolls do not support a sophisticated reliable datatransfer which leads to a significant increased message overhead. In
this research field we develop a protocol for reliable and thereby dependable datatransfer over MANETs. This work is supported
by a DEDIS studentship. Our current test bed is a setup in cooperation with LAFIM.
Image
Fig.1: Summerschool "Zuverlässige Systeme"
Speakers: Partner of the DEDIS-NanoClass, 10.-11.09.2009
Publications
KopAN - Bidirectional Acoustical Communication Via MANETs
Sebastian Fudickar, Klaus Rebensburg and Bettina Schnor
In Proceedings of the 6th Wireless Communication and Information conference
Germany, Berlin, October 2009
MANETSip - A Dependable SIP Overlay Network for MANET Including Presentity Service
Sebastian Fudickar, Klaus Rebensburg and Bettina Schnor
In Proceedings of the 5th International conference on Networking and Services
Valencia, Spain, April 2009